UW Interactive Data Lab
papers
ScatterShot: Interactive In-context Example Curation for Text Transformation
Tongshuang (Sherry) Wu, Hua Shen, Jeffrey Heer, Daniel S. Weld, Marco Tulio Ribeiro.
Proc. ACM Intelligent User Interfaces, 2023
Proc. ACM Intelligent User Interfaces, 2023
Materials
PDF | Honorable Mention Award
Abstract
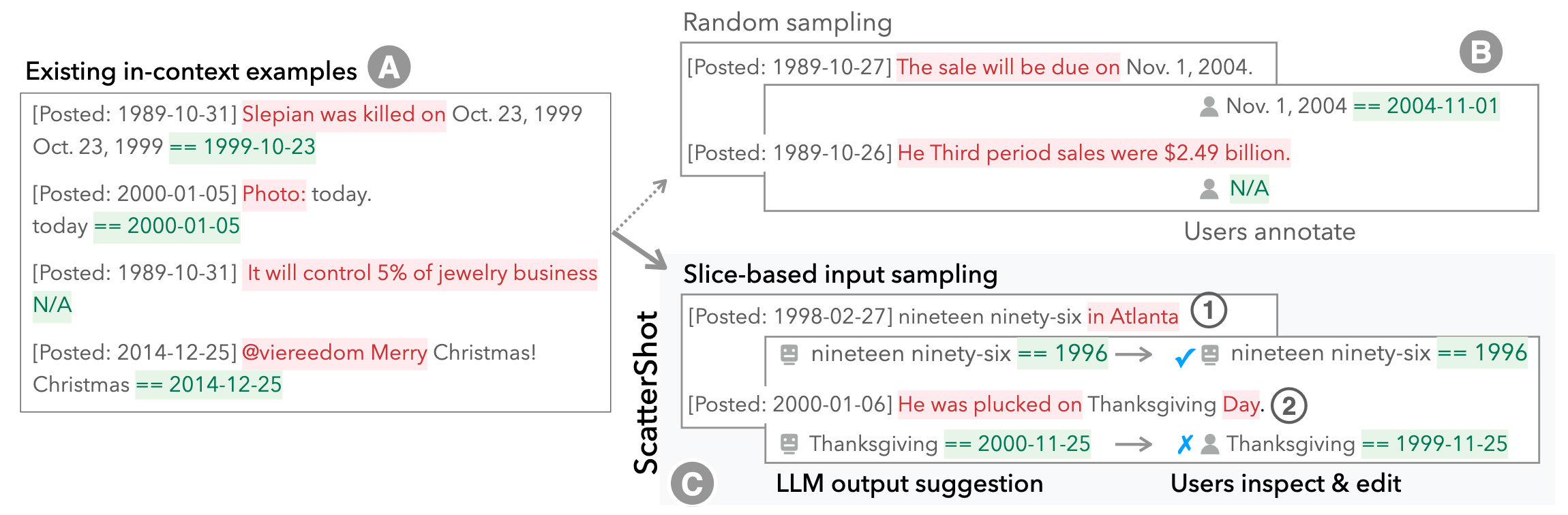
The in-context learning capabilities of LLMs like GPT-3 allow annotators to customize an LLM to their specific tasks with a small number of examples. However, users tend to include only the most obvious patterns when crafting examples, resulting in underspecified in-context functions that fall short on unseen cases. Further, it is hard to know when “enough” examples have been included even for known patterns. In this work, we present ScatterShot, an interactive system for building high-quality demonstration sets for in-context learning. ScatterShot iteratively slices unlabeled data into task-specific patterns, samples informative inputs from underexplored or not-yet-saturated slices in an active learning manner, and helps users label more efficiently with the help of an LLM and the current example set. In simulation studies on two text perturbation scenarios, ScatterShot sampling improves the resulting few-shot functions by 4-5 percentage points over random sampling, with less variance as more examples are added. In a user study, ScatterShot greatly helps users in covering different patterns in the input space and labeling in-context examples more efficiently, resulting in better in-context learning and less user effort.
BibTeX
@inproceedings{2023-scattershot,
title = {ScatterShot: Interactive In-context Example Curation for Text Transformation},
author = {Wu, Tongshuang AND Shen, Hua AND Heer, Jeffrey AND Weld, Dan AND Ribeiro, Marco},
booktitle = {Proc. ACM Intelligent User Interfaces},
year = {2023},
url = {https://idl.uw.edu/papers/scattershot},
doi = {10.1145/3581641.3584059}
}