UW Interactive Data Lab
papers
Hypothesis Formalization: Empirical Findings, Software Limitations, and Design Implications
Eunice Jun, Melissa Birchfield, Nicole de Moura, Jeffrey Heer, René Just.
ACM Trans. on Computer-Human Interaction, 2022
ACM Trans. on Computer-Human Interaction, 2022
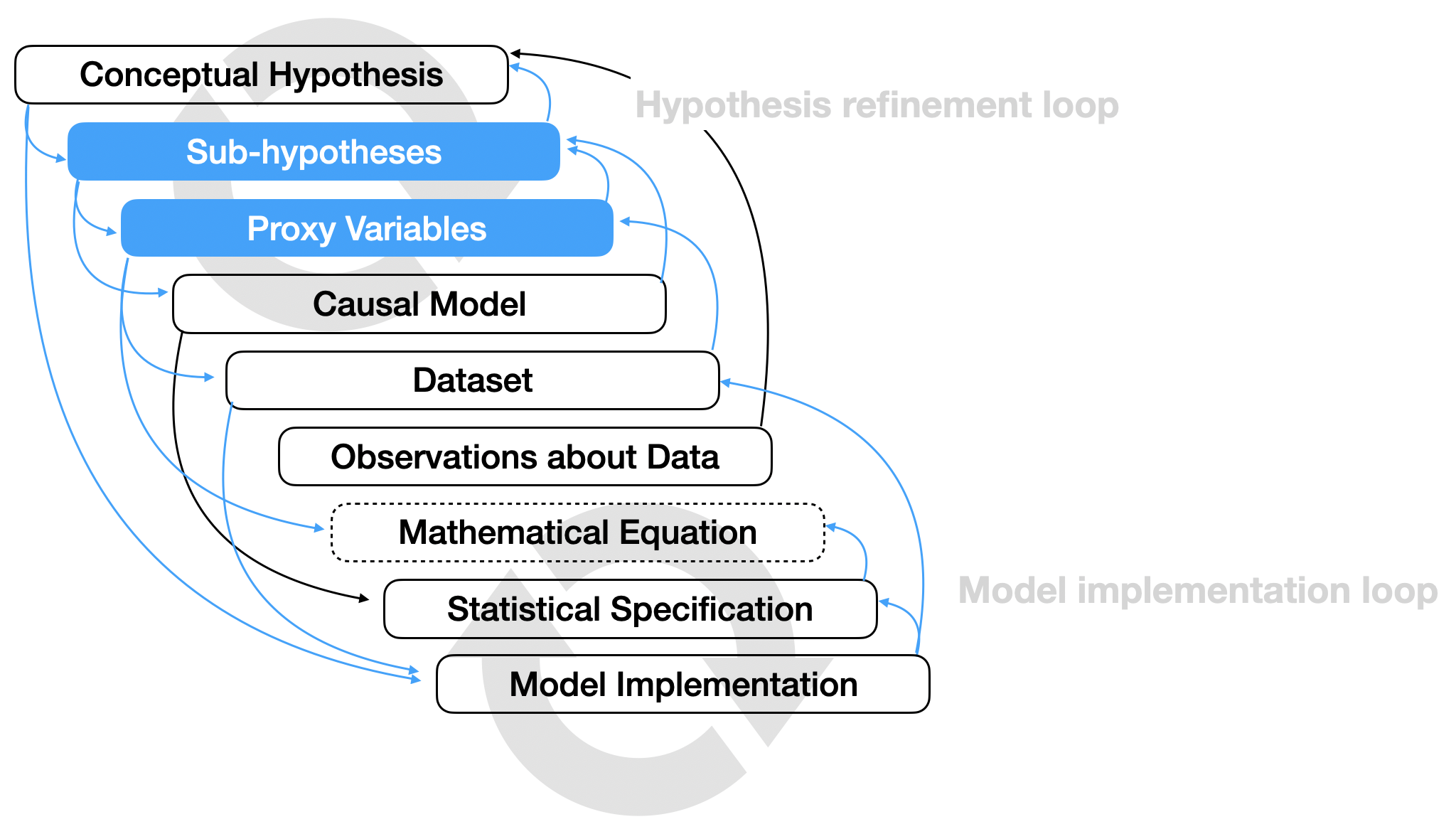
Materials
Abstract
Data analysis requires translating higher level questions and hypotheses into computable statistical models. We present a mixed-methods study aimed at identifying the steps, considerations, and challenges involved in operationalizing hypotheses into statistical models, a process we refer to as hypothesis formalization. In a formative content analysis of 50 research papers, we find that researchers highlight decomposing a hypothesis into sub-hypotheses, selecting proxy variables, and formulating statistical models based on data collection design as key steps. In a lab study, we find that analysts fixated on implementation and shaped their analyses to fit familiar approaches, even if sub-optimal. In an analysis of software tools, we find that tools provide inconsistent, low-level abstractions that may limit the statistical models analysts use to formalize hypotheses. Based on these observations, we characterize hypothesis formalization as a dual-search process balancing conceptual and statistical considerations constrained by data and computation and discuss implications for future tools.
BibTeX
@article{2022-hypothesis-formalization,
title = {Hypothesis Formalization: Empirical Findings, Software Limitations, and Design Implications},
author = {Jun, Eunice AND Birchfield, Melissa AND Moura, Nicole AND Heer, Jeffrey AND Just, Ren\'{e}},
journal = {ACM Trans. on Computer-Human Interaction},
year = {2022},
volume = {29},
number = {1},
editor = {Kristina Hook},
pages = {1--28},
url = {https://idl.uw.edu/papers/hypothesis-formalization},
doi = {10.1145/3476980}
}