UW Interactive Data Lab
papers
Errudite: Scalable, Reproducible, and Testable Error Analysis
Tongshuang (Sherry) Wu, Daniel S. Weld, Jeffrey Heer, Marco Tulio Ribeiro.
Proc. Association for Computational Linguistics (ACL), 2019
Proc. Association for Computational Linguistics (ACL), 2019
Abstract
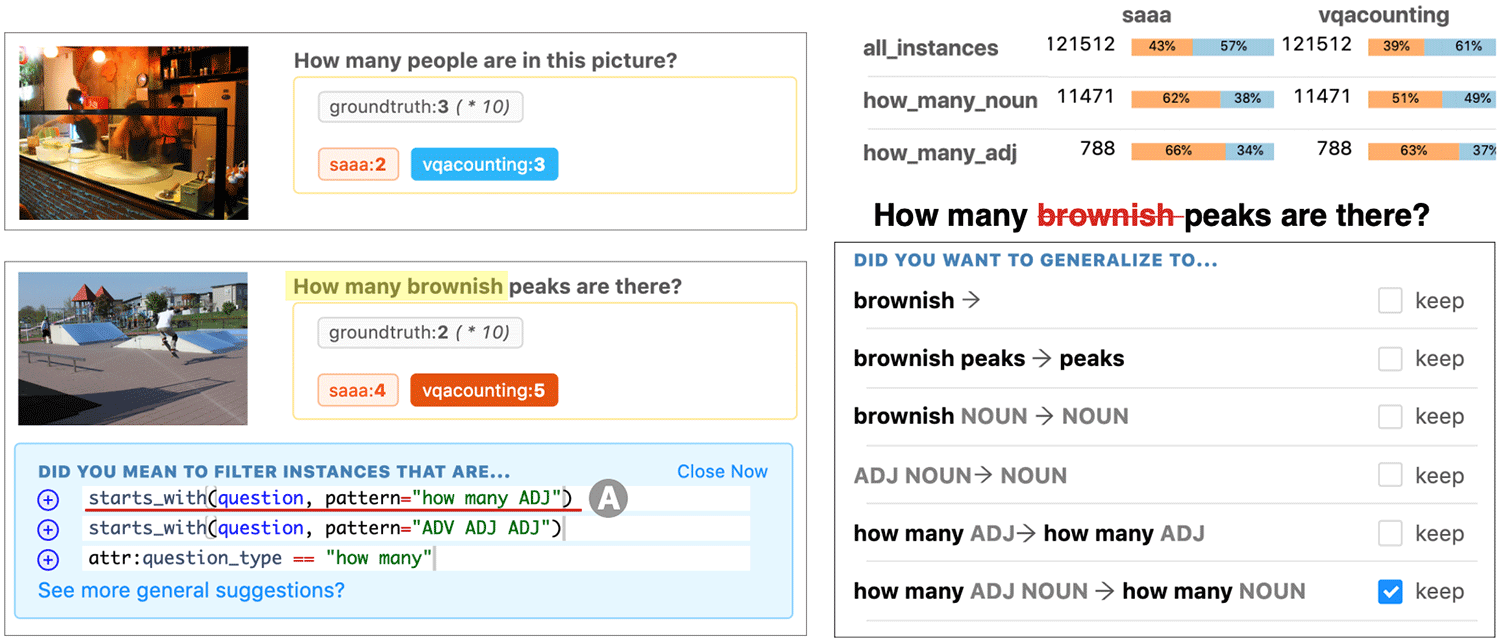
Though error analysis is crucial to understanding and improving NLP models, the common practice of manual, subjective categorization of a small sample of errors can yield biased and incomplete conclusions. This paper codifies model and task agnostic principles for informative error analysis, and presents Errudite, an interactive tool for better supporting this process. First, error groups should be precisely defined for reproducibility; Errudite supports this with an expressive domainspecific language. Second, to avoid spurious conclusions, a large set of instances should be analyzed, including both positive and negative examples; Errudite enables systematic grouping of relevant instances with filtering queries. Third, hypotheses about the cause of errors should be explicitly tested; Errudite supports this via automated counterfactual rewriting. We validate our approach with a user study, finding that Errudite (1) enables users to perform high quality and reproducible error analyses with less effort, (2) reveals substantial ambiguities in prior published error analyses practices, and (3) enhances the error analysis experience by allowing users to test and revise prior beliefs.
BibTeX
@inproceedings{2019-errudite,
title = {Errudite: Scalable, Reproducible, and Testable Error Analysis},
author = {Wu, Tongshuang AND Weld, Dan AND Heer, Jeffrey AND Ribeiro, Marco},
booktitle = {Proc. Association for Computational Linguistics (ACL)},
year = {2019},
url = {https://idl.uw.edu/papers/errudite},
doi = {10.18653/v1/p19-1073}
}